4.8
Beschikbaar van 08:30 tot 17:00
Beschikbaar van 08:30 - 17:00
In de context van SEO betekent indexeerbaar dat een website of een pagina gevonden én geïndexeerd kan worden door de zoekmachines. Dit gebeurt door middel van crawlers en wordt ook wel crawlability, indexability of indexeerbaarheid genoemd.
In deze blog:
Indexeerbaar betekent dus het vinden en indexeren van nieuwe web content. Bijvoorbeeld van een nieuwe of een bijgewerkte website pagina. Daarvoor maken de zoekmachines gebruik van web crawlers. Deze bekijken de gevonden pagina’s en volgen de aanwezige links. De gegevens worden vervolgens overgebracht naar de servers van de zoekmachine. Zoekmachines gebruiken de crawlability en de indexeerbaarheid om pagina’s te vinden en te indexeren. Vervolgens zijn ze dus te indexeren en worden ze toegevoegd aan de index.
Beschrijft het vermogen van de zoekmachine om toegang te krijgen tot de inhoud van een pagina en deze te crawlen. Als een website naar behoren werkt, kunnen web crawlers de content makkelijk vinden door de links tussen de pagina’s te volgen. Links die niet goed functioneren kunnen problemen veroorzaken met de crawlability. Op dat moment kan de zoekmachine de specifieke content op een website moeilijk benaderen.
Indexeerbaarheid verwijst naar het vermogen van de zoekmachine om een pagina te analyseren en aan zijn index toe te kunnen voegen. Als een website problemen heeft met de indexeerbaarheid, kan de zoekmachine de website wel crawlen. Maar, mogelijk is het niet in staat om alle pagina’s van de betreffende website te kunnen indexeren.
De informatiestructuur van de website speelt een belangrijke rol bij de crawlability. Als een website pagina’s bevat die niet doorlinken, hebben de crawlers moeite om deze te vinden. Ze kunnen wel worden gevonden via externe links, mits iemand er in zijn content naar verwijst. Vaak veroorzaakt een zwakke informatiestructuur problemen met de crawlability.
Door links te volgen kan een web crawler het internet doorkruisen. Daarom kunnen de crawlers alleen de pagina's vinden waarnaar wordt gelinkt vanuit andere content. Een correcte interne linkstructuur zorgt ervoor dat de crawlers ook de pagina’s kan bereiken die verborgen liggen in de structuur van een website. Een slechte linkstructuur kan de crawlers juist op een doodlopend spoor zetten. Daardoor missen de crawlers een deel van de inhoud.
Crawlability problemen kunnen ook worden veroorzaakt door redirects. Deze onderbrekingen naar een pagina kunnen een web crawler tegenhouden omdat de nieuwe pagina niet kan worden gevonden. Zorg dus altijd voor werkende 301 redirects.
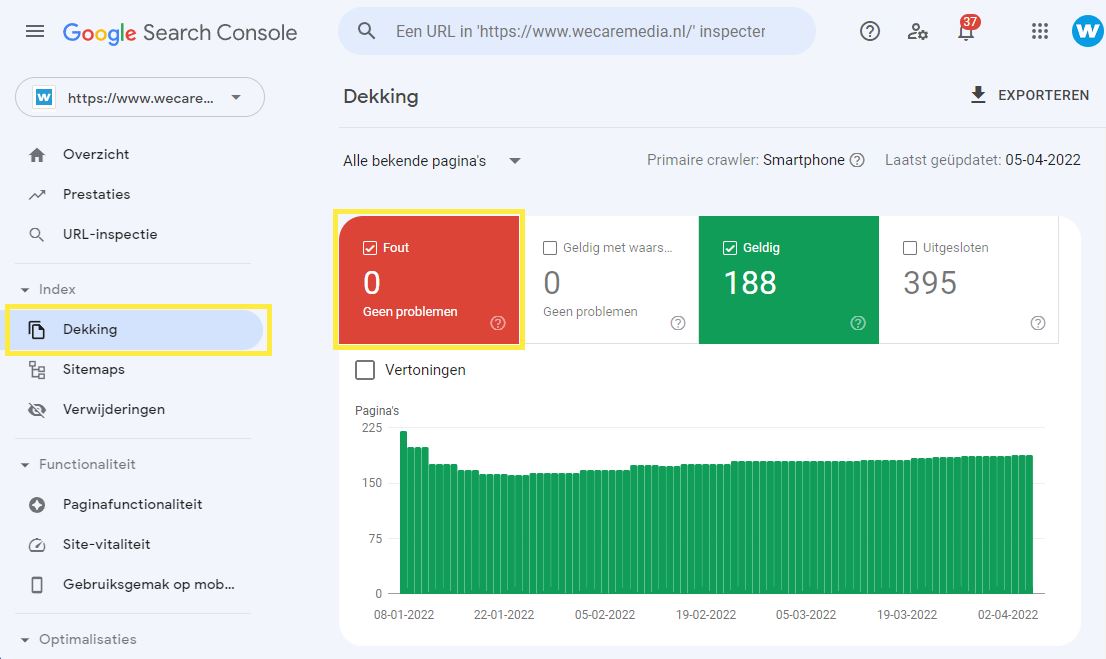
Foutieve server redirects en andere server gerelateerde problemen kunnen voorkomen dat de web crawlers toegang krijgen tot alle content. Om te controleren of je website serverfouten bevat kun je gebruik maken van Google Search Console.
Je kunt in de Google Search Console de serverfouten zien door op: "Dekking" te klikken en vervolgens: "Fouten" te selecteren.
Ook de technologie die op een website wordt gebruikt kan problemen veroorzaken met de crawlability. Web crawlers kunnen bijvoorbeeld geen formulieren volgen. In dat geval zal het verbergen van content achter een formulier voor crawlability problemen kunnen zorgen. Ook scripts kunnen de content blokkeren voor de crawlers. Zoals bijvoorbeeld JavaScript.
Je kunt de web crawlers ook doelbewust blokkeren. Bijvoorbeeld als je niet wilt dat de pagina’s op jouw website worden geïndexeerd. Daar zijn een aantal redenen voor. Bijvoorbeeld als je een pagina hebt gemaakt die niet toegankelijk is voor bezoekers.
Je moet deze pagina dan ook uitsluiten voor de zoekmachines en de web crawlers. Als je dit doet is voorzichtigheid geboden. En foutje in de code is namelijk zo gemaakt. Dit leidt ertoe dat je een deel van de website blokkeert voor de crawlers.
Als je pagina's uitsluit van indexatie wil dat niet zeggen dat iemand de pagina niet kan bezoeken. Als je de directe URL van een pagina weet kun je de pagina gewoon bekijken!
Als je wilt dat jouw website eenvoudig te indexeren is, kun je in de eerste plaats rekening houden met de bovenstaande punten. Toch kun je de web crawlers ook op andere manieren helpen om de pagina's eenvoudig te kunnen openen en indexeren.
De sitemap bevindt zich in de hoofdmap van een domein. Het is een klein bestand dat directe links bevat naar elke pagina op een website. Je kunt een sitemap bij de zoekmachine indienen door gebruik te maken van de Google Console. Het bestand of de sitemap geeft Google de informatie die het nodig heeft over jouw content. Daarnaast waarschuwt een sitemap ook wanneer er sprake is van bewerkingen of updates.
In onze blog: "Sitemap indienen via Google Search Console" kun je lezen hoe dit werkt.
Interne links beïnvloeden de crawlability van een website. Als je zeker wilt weten dat de web crawlers van Google alle content op een site vinden, moet je de links tussen de pagina's verbeteren. Zo zorg je ervoor dat alle content met elkaar verbonden is.
Content is het belangrijkste onderdeel van een website. Daarmee kun je bezoekers aantrekken, je bedrijf voorstellen aan het publiek om ze vervolgens om te zetten in klanten.
Content draagt ook bij aan het verbeteren van de crawlability van een website. Websites die vaker worden bijgewerkt of ge-update, worden vaker bezocht door de web crawlers. Dat betekent dat ze een pagina veel sneller zullen crawlen en indexeren.
Duplicate content heeft een negatieve invloed op de ranking binnen de zoekmachine. Duplicate content zijn pagina’s die dezelfde of sterk vergelijkbare content bevatten. Dubbele inhoud verlaagt ook de frequentie waarmee crawlers een website bezoeken. Het is dus belangrijk om duplicate content op een website te voorkomen of te herstellen.
Web crawlers hebben in de meeste gevallen maar een beperkte tijd die ze kunnen besteden aan het crawlen en indexeren van een website. Dit wordt ook wel een crawl-budget genoemd. Dat betekent dat de crawlers een website verlaten zodra de tijd om is. Het is dus belangrijk om de laadtijd van een pagina te verbeteren en te versnellen. Des te sneller een pagina laadt, des te meer informatie een crawler kan verzamelen binnen de gestelde tijd.
Heb je hulp nodig met het verbeteren van de laadtijd van je website? Of wil je een nieuwe website waar goed over nagedacht is qua structuur, techniek en crawlability? Wij helpen je uiteraard graag verder
Als je inlogt bij de Google Search Console krijg je een gedetailleerd overzicht van al je geïndexeerde pagina's, problemen en posities in Google.
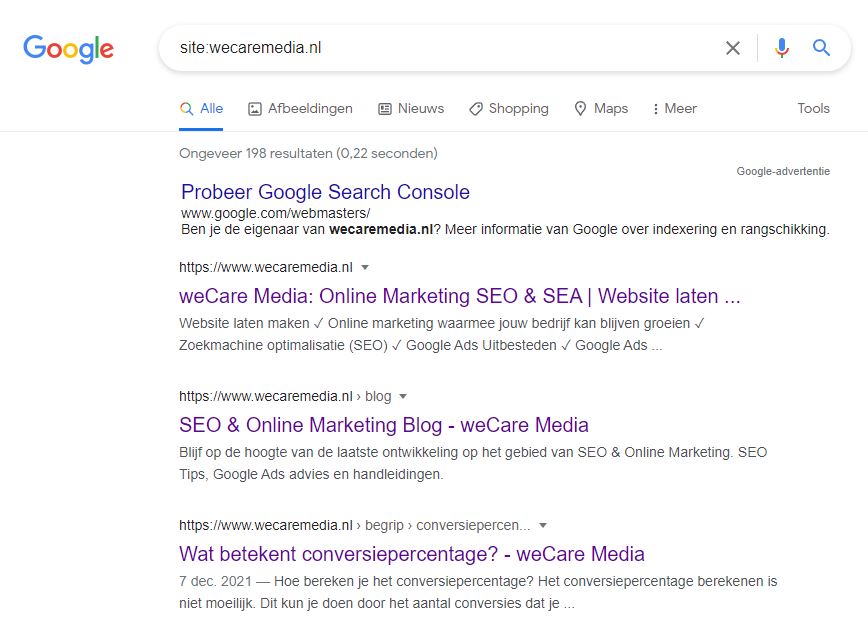
Een snellere en eenvoudigere manier om te controleren welke pagina's er van je website geindexeerd zijn is door naar www.google.nl te gaan en te zoeken op: "site:domeinnaam.nl". Je kunt dit ook met een specifieke URL van een pagina doen om te kijken of de pagina is geindexeerd.
 Dwayne Snoeren
Dwayne Snoeren
Wij ontwerpen en bouwen websites die scoren in Google én klanten opleveren. Bel ons op: 085 - 303 81 81